Classification
Classification block setup (Setup button) |
 |
Classification block performs one of the classification algorithms on the input vectors of the events from DataSet blocks connected to the input (left >> button) and sends resulting data to the DataSet blocks connected do the output (right >> button). Events in the output DataSets are constructed according to the output format mapping and filter rules. Similarly to the Network block, results are also stored in the output vectors of the events in the input DataSets.
Each classification algorithm uses training sets that are contained in DataSet pointed in the block's setup. Events in the training set must contain target vectors indicating event class. Target vector should consist of one element (label) in case of two-class separation tasks; values recognized as the signal: 1.0, 0.95, 0.9; other values are treated as the background. Multi-class separation requires target vector length equal to the number of recognized classes. Each event has to be marked in the target vector with signal value placed on a position corresponding to its class.
Values returned as the result of the classification of the event x are estimators of the conditional likelihood:
outputC(x) ≈ P(x ∈ C | x = input) = gC(x)∙pC / ∑[gi(x)∙pi]
where gi(x) are the probability distribution functions and pi are a priori likelihoods.
To add the Classification block to the project, choose menu Edit - Add Component - Classification
Classification block setup (Setup button)
Apply button saves all parameters but doesn't start processing; Go! button saves parameters and starts processing, it is enabled only in manual trigger mode.Other controls are grouped in tabs: general info, algorithm setup, output format and filter setup, and triggering setup.
general info
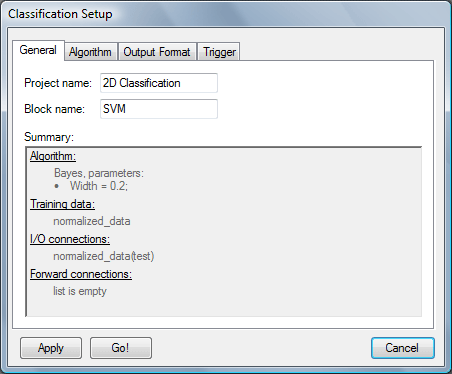
Block and project names may be chnged here (names should not contain "\" symbols).
Summary shows the current block setup.
algorithm setup
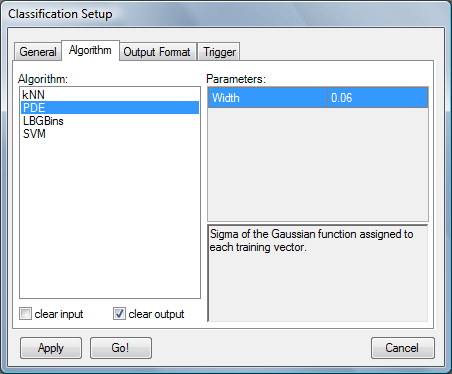
Classification algorithms:
kNN: k nearest neighbours; algorithm calculates outputs basing on the number of signal events among the k training events with the smallest distance to the classified event. It is simple, relatively fast and well known algorithm, but don't expect outstanding results in multidimensional feature spaces.
PDE: Class probability density distributions are estimated as a sums of the gaussian functions centered over the events from the training set. Then conditional likelihood is calculated directly from the formula. Width of the gaussian functions is the user defined parameter. Algorithm is extremely time-consuming but gives a bit more reliable results than kNN (especially for high-dimensional input vectors).
LBGBins: Space of the training vectors is quantized with the LBG algorithm to obtain N representative vectors. These vectors become centroids of N sectors with uniform conditional likelihood calculated as a ratio of signal to background training events in the given sector (bin). Classified events are assigned to the nearest centroid and, in result, use its pre-calculated likelihood.
SVM: Support Vector Machines based on the SVM.NET library.
Remember: in most cases it is necessary to do some preprocessing - N(0,1) normalization at least; this applies for all implemented algorithms.
clear input: Input DataSets will be cleared after processing.
clear output: Output DataSets will be cleared before processing. If unchecked - new events will be attached to the existing ones.
output forward and filter setup
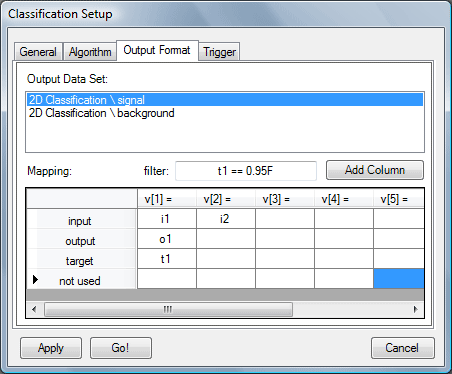
When classification of the events from input DataSets is done, theirs contents is sent to the output DataSets, according to the output format mapping specifications. Destination events in each output DataSet may be composed in the different way. Select the DataSet in the Output Data Set list and put desired expression for the destination event vector elements. Simple example in the image above does:
Events stored in the output DataSets can be filtered (only events with thedestination event input vector will be composed of the first and second element of the source event input vector; destination event output vector will be created with the length=1 and it will contain first element of the classification output vector; destination event target will contain copy of the first element of the source target vector. t1=0.95Fwill be sent to the signal DataSet in the example above).
triggering setup
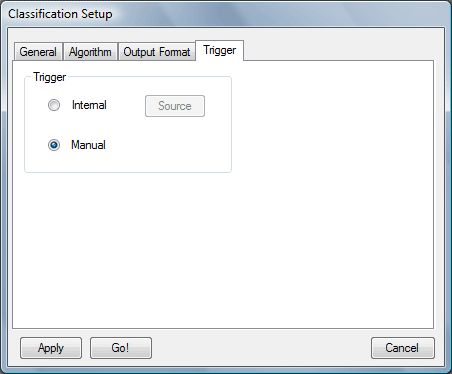
If manual mode is selected, Go! button is enabled and it releases classification calculations. If internal mode is chosen - Source button is enabled and it allows to select the source of the trigger through the common Connection Add dialog window (Go! button is disabled); processing starts when one of the selected sources finished its own task.
Input list (left >> button)
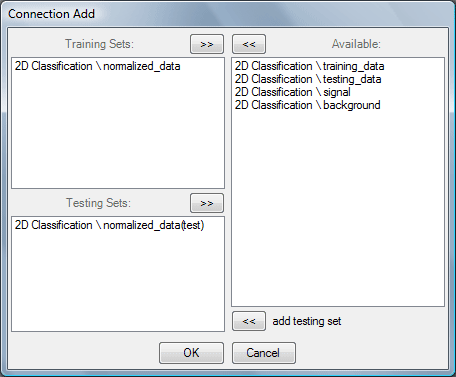
Left button >> button opens the list of the training and testing DataSets (extended Connection Add dialog window). Double-click on the item from the Available list adds new training set. Use lower << button to add new item to the Testing sets list. Double-click on the item from the Training Sets or Testing Sets lists removes connection.
Output list (right >> button)
Connects the output of the Classify block to the destination DataSets. Opens common Connection Add dialog window.